
本文讲解如何在个人电脑上快速部署DeepSeek模型,并基于RAG技术搭建个人知识库。
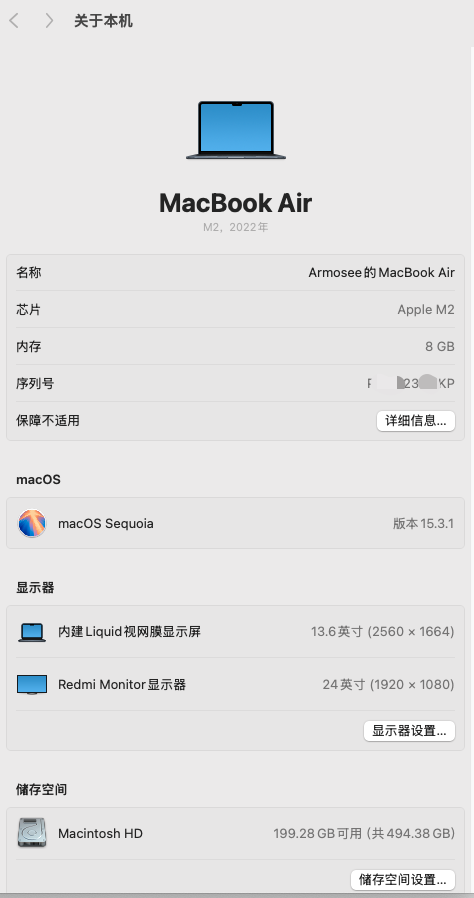
0.个人电脑配置

1.Ollama安装
Ollama是一款可实现在本地部署大模型的工具,支持目前主流的开源大模型,如deepseek、Qwen、Llama3等。在MAC、Windows、Linux操作系统上均可安装。
本地部署大模型的工具还有很多,比如LM studio等,我推荐Ollama。
Ollama官网如下:
点击Download进行下载,并双击安装,将软件图标拖动到应用中,即可安装。
2.大模型部署
使用Ollama工具进行本地大模型部署非常简单。
- 打开mac 终端

- 在终端中输入命令:ollama run deepseek-r1:7b,ollama便可以自动进行大模型的下载和安装,安装完成之后直接运行大模型,可以在终端内直接进行大模型交互。

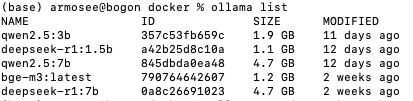
- 经过试验,7b参数量的模型,在我的个人电脑上运行非常卡顿,1.5b模型是比较顺畅的。我安装的模型如下:
但是,使用终端进行输出,界面不甚友好,因此我们安装AnythingLLM,对大模型进行可视化,同时引入个人知识库。
3.大模型本地可视化-AnythingLLM
- 进入AnythingLLM的官网:https://anythingllm.com,点击下载。
- 根据你机器不同操作系统和芯片,点击对应版本进行下载,我选择MacOs的Apple芯片版本进行下载。
- 下载完成之后,双击安装,将图标拖到应用程序中完成安装。
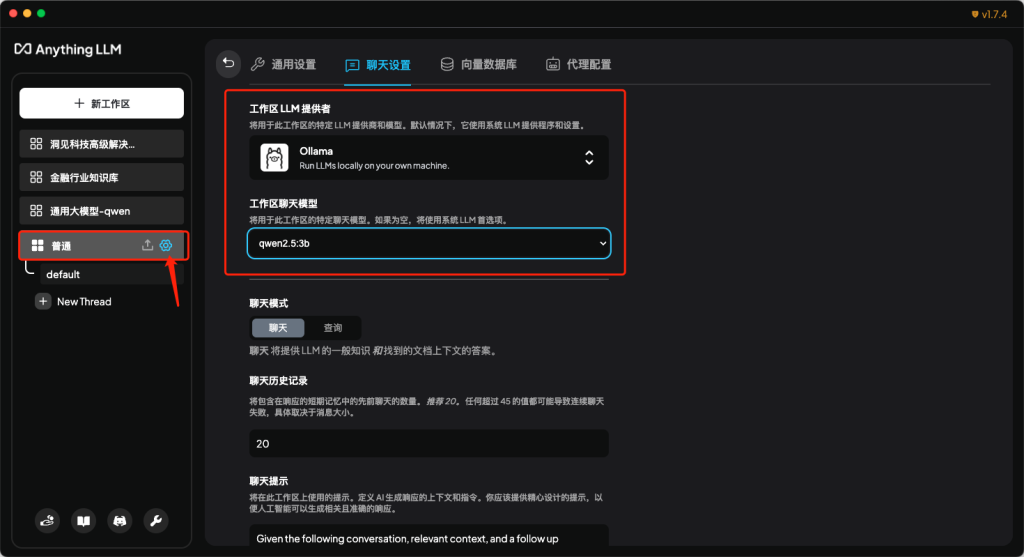
- 打开软件,在首页点击小扳手图标,进行大模型通用项配置。
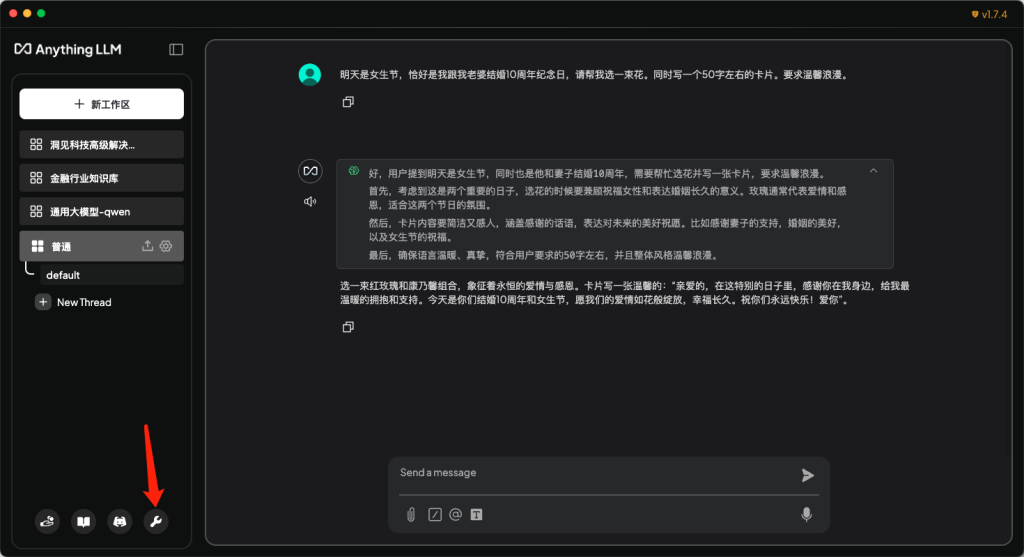
- 在菜单栏中,找到人工智能提供商-LLM首选项,在页面中将LLM提供商修改为Ollama,也就是使用Ollama作为大模型的部署工具,安装的所有大模型都可以选择。然后在Ollama Model中选择使用的模型。其他参数可保持默认。在进行此项配置时,需要保证Ollama软件正在运行,否则会报错。
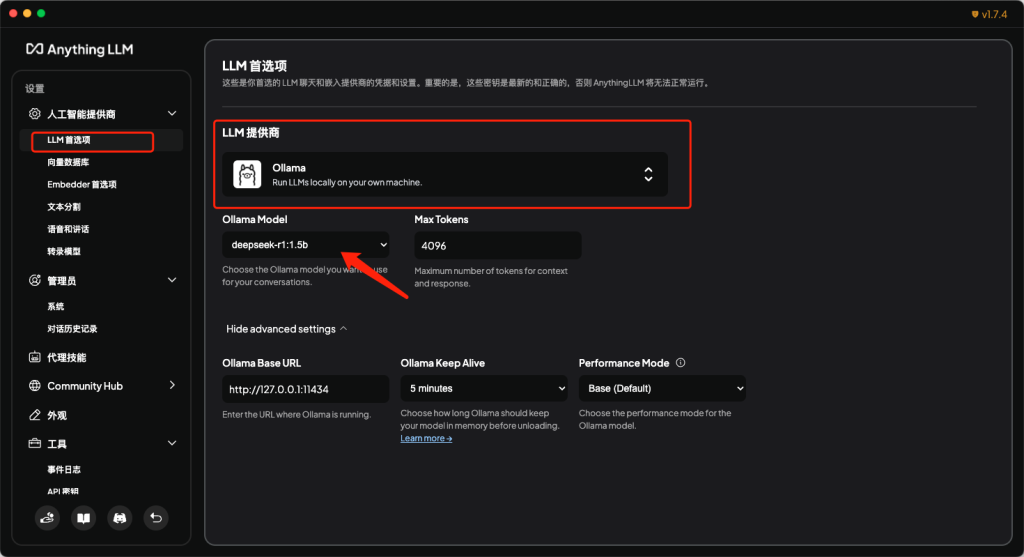
- 此时,我们点击返回按钮,回到主页面。并在主页面中点击新建工作区,来进行大模型的可视化页面应用。
- 工作区的作用:工作区可以将工作环境进行隔离,比如配置不同的大模型和其他参数,有助于在不同的任务中,发挥不同大模型的优势,未来可用于不同领域知识库的搭建。
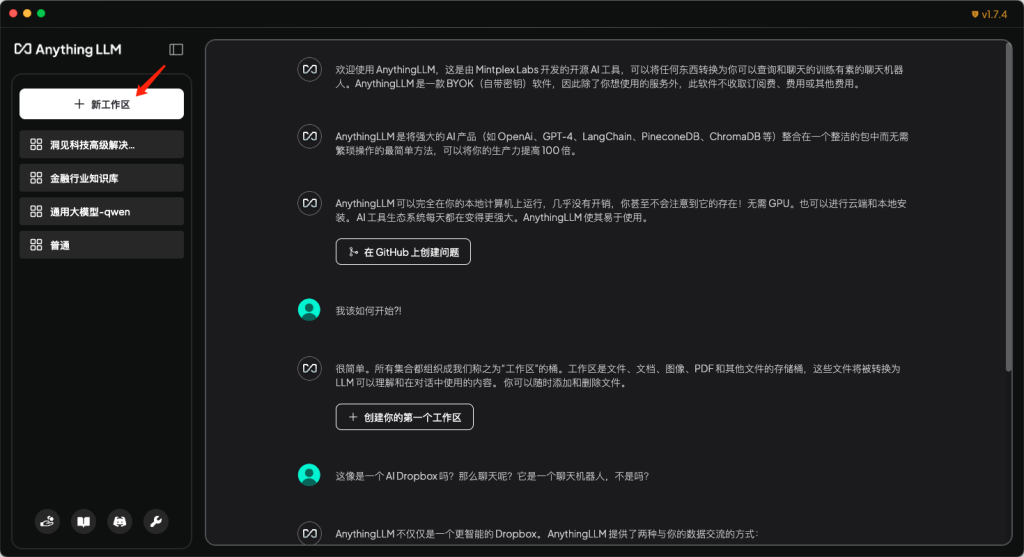
- 在我新建的命名为普通的工作区中,在聊天设置中依然可以选择跟通用设置不同的大模型,并可以设置短期记忆的消息数量。
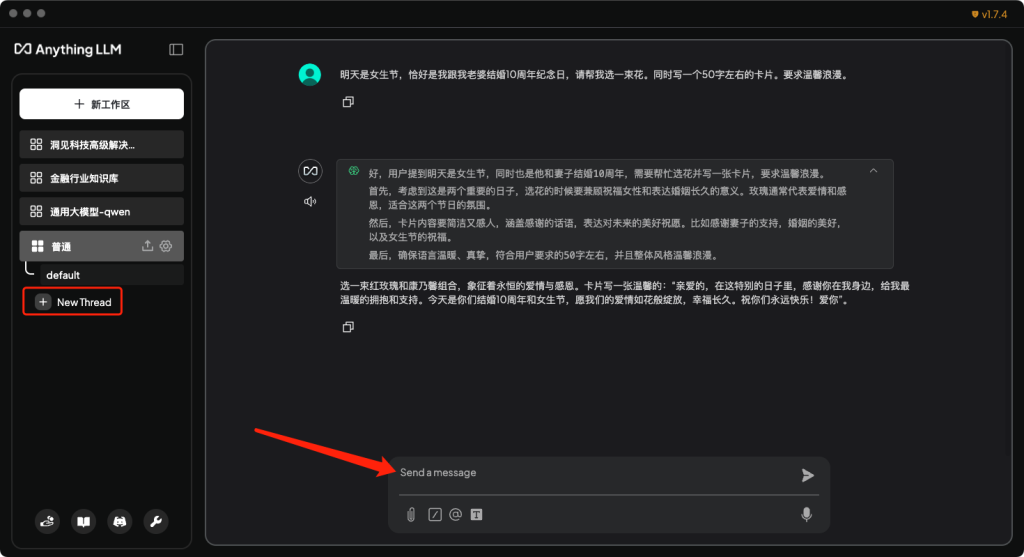
- 在工作区下面,可以使用模型聊天,或者新建聊天,来开始与大模型的交互吧。
4.本地知识库搭建
本章节中,使用RAG搜索增强生成的技术,来让大模型成为一个专业领域的专家。
因为目前的大模型都是通用大模型,往往在某些垂直领域缺乏基本的专业知识,无法胜任专业领域的工作,通过RAG(搜索增强生成)技术,相当于给了大模型一个智囊库,就可以让大模型看起来更能胜任专业领域的工作。或者说大模型的知识只是截止到某一个具体时间点,比如deepseek的知识是截止到2024年7月的,后续的知识它没有,只能通过RAG或者微调的方式进行模型优化迭代。
我们依然使用AnythingLLM来实现RAG本地知识库的搭建。
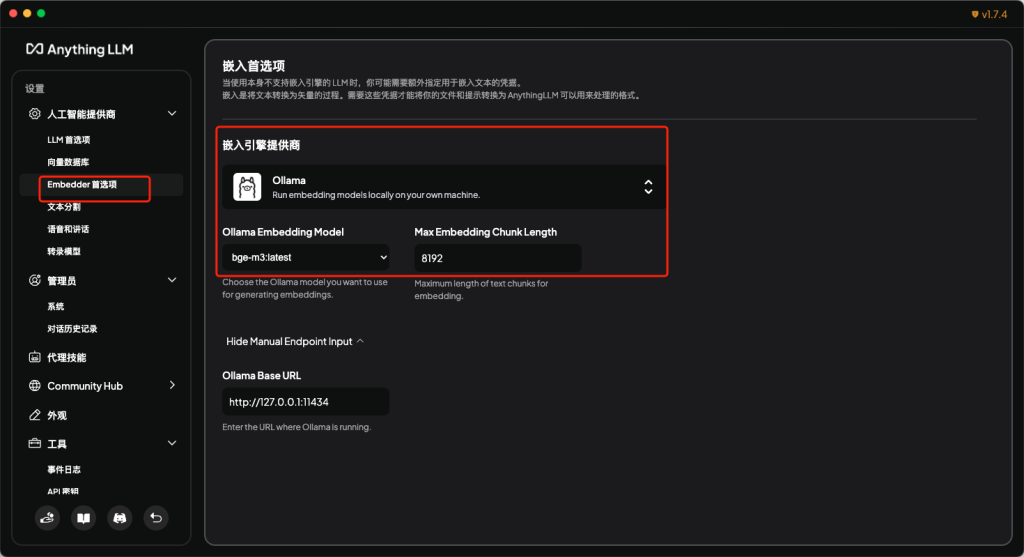
- 首先,因为需要对输入的文档进行分块处理,并加入到向量数据库,因此我们需要一个embedding model。我们可以使用Ollama进行bge-m3:latest模型的安装。
- 然后在通用配置中,找到Embedder首选项,并使用Ollama作为嵌入引擎提供商,选择刚才安装的bge-m3:latest模型作为EmbeddingModel。其他参数都可以先默认。
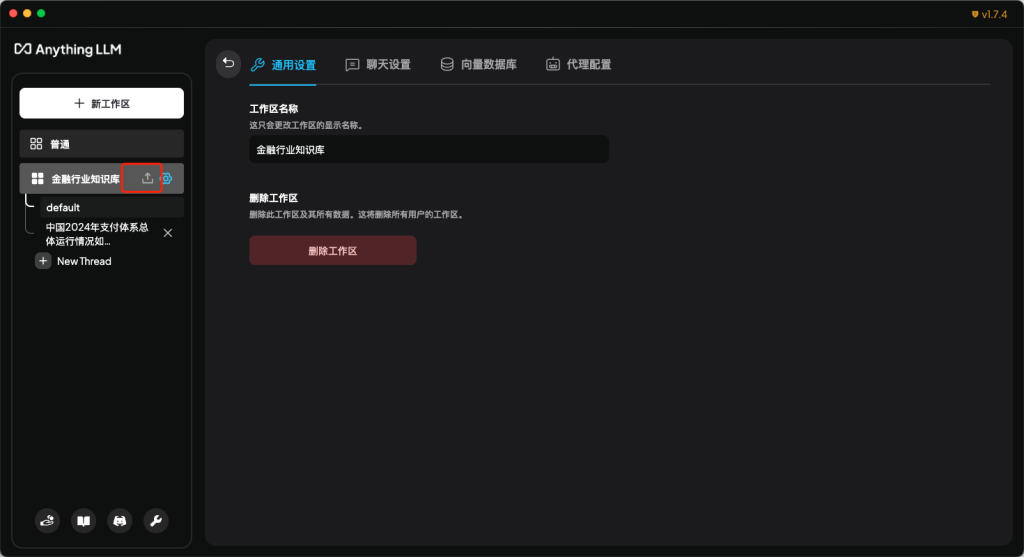
- 其次,我们新建一个金融知识库的工作空间。并点击文档上传按钮,进行知识库文档的上传。
- 在上传文档页面,可以将需要上传的文档拖入到指定区域,或者直接填入需要查询的网址。
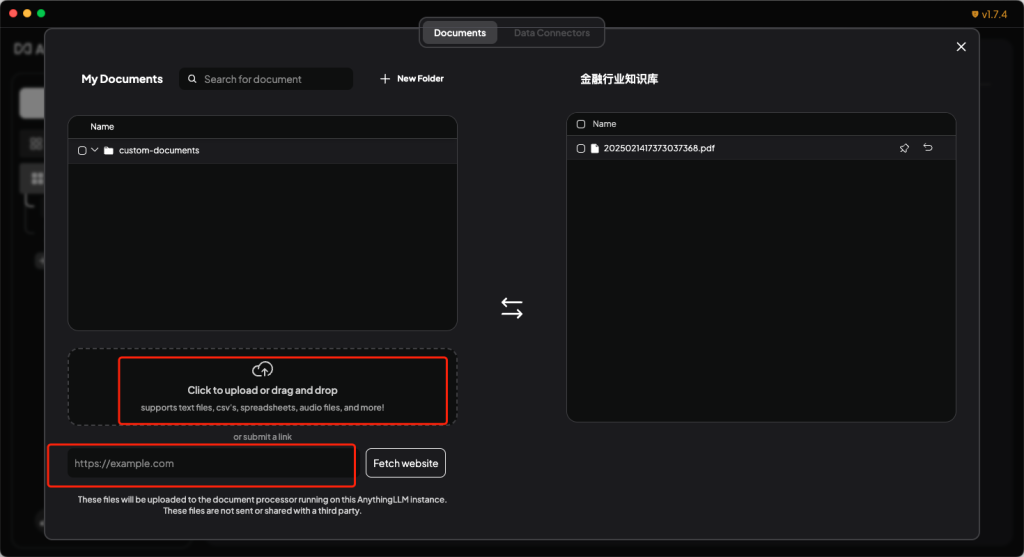
- 点击上传文档后面的cached按钮,并点击move to Workspace。
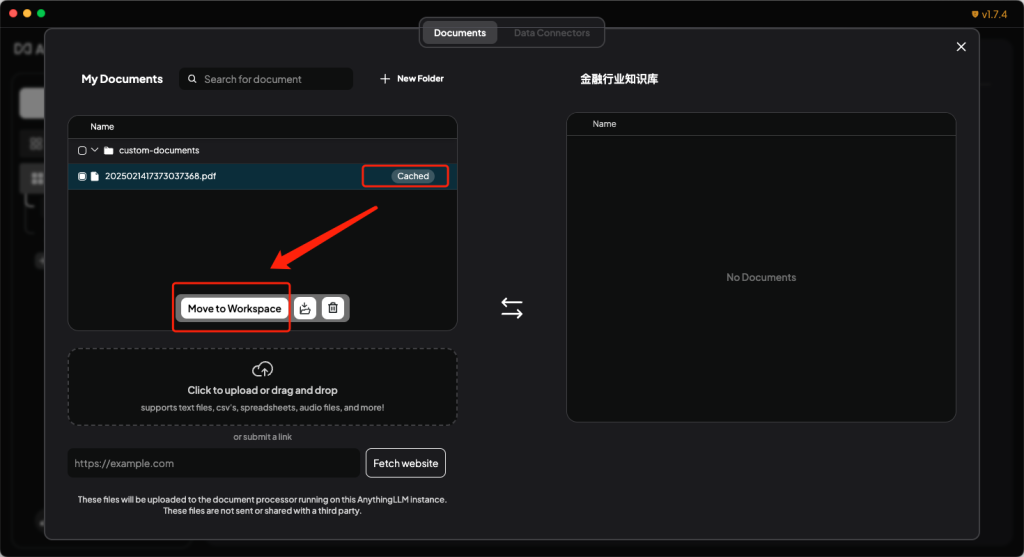
- 点击save and Embed按钮,进行文档的解析和保存工作。完成之后,就可以在与大模型的对话中,询问跟知识库相关的专业知识了。
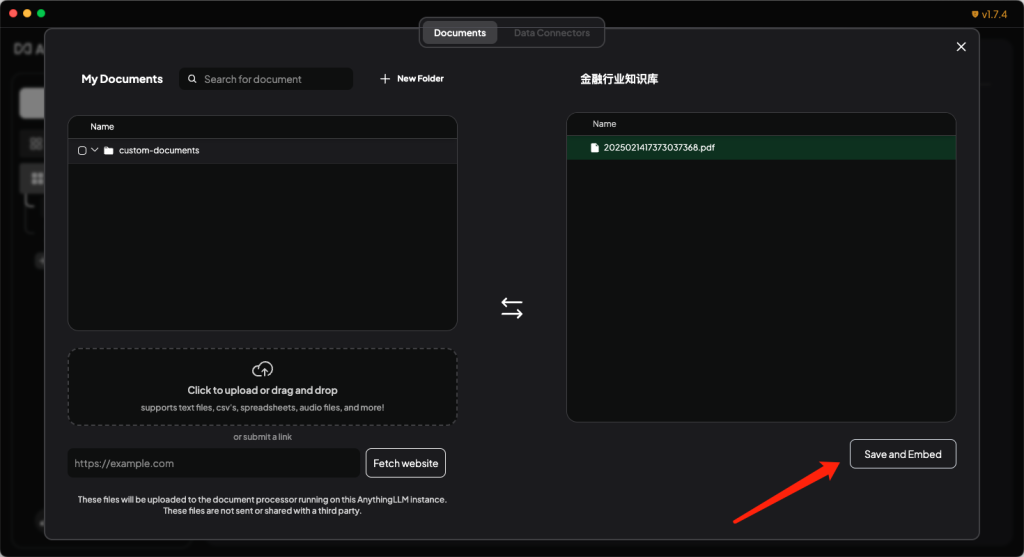
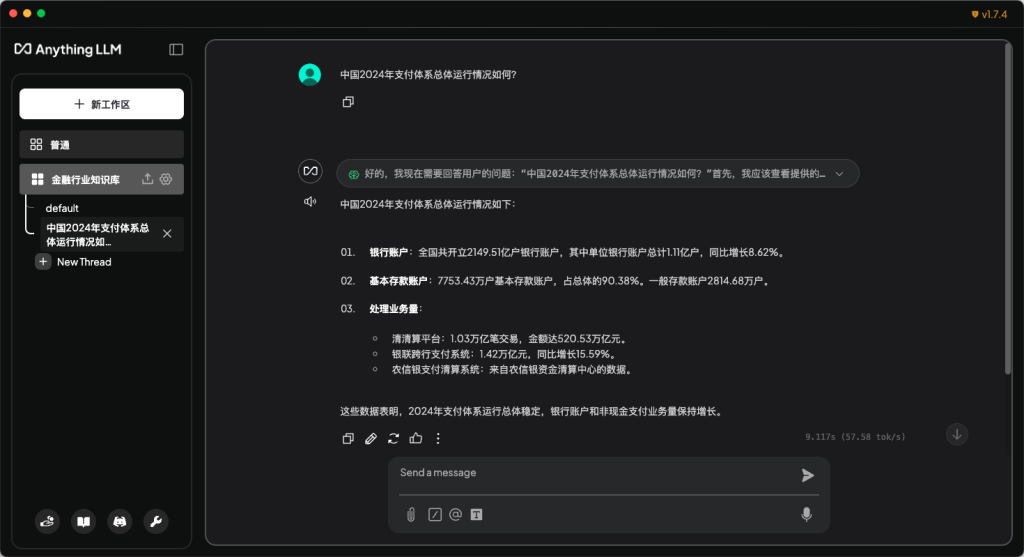
当然,如果希望RAG知识库更加好用,还需要不断调整和优化各个参数。比如向量数据库的精细化配置、embedding模型的选择和优化等等。
发表回复